Ihre CI/CD-Pipeline hat soeben einen KI-Agenten deployed. Er verfügt über einen Service-Account, einen langlebigen API-Key und Zugriff auf Ihre Produktionsdatenbank, Ihren Slack-Workspace und Ihre GitHub-Organisation. Niemand hat ein Ticket erstellt. Niemand hat den Scope geprüft. Der Agent ist live - und Ihr IAM-System weiß nicht einmal, dass er existiert.
Das ist kein hypothetisches Szenario. Eine Umfrage aus dem Jahr 2026 unter 919 Führungskräften und Fachleuten ergab, dass 82 % der Führungskräfte zuversichtlich sind, ihre bestehenden Richtlinien / Policies schützten sie vor unautorisierten Agenten-Aktionen - tatsächlich werden jedoch nur 47,1 % der KI-Agenten einer Organisation überwacht oder abgesichert[1]. Mehr als die Hälfte aller deployed Agenten operiert ohne jegliche Sicherheitsüberwachung oder Protokollierung. Das Vertrauen ist eine Illusion.
Dieser Guide richtet sich an Platform- und Dev-Tooling-Engineers, die diese Lücke schließen müssen - ohne jedes Agenten-Deployment in einen dreiwöchigen Genehmigungsprozess zu verwandeln.
Warum KI-Agenten klassisches IAM aushebeln
Klassisches IAM wurde auf einem einfachen Modell aufgebaut: Ein Mensch meldet sich an, erhält eine Session, erledigt seine Arbeit, meldet sich ab. Mit autonomen Agenten bricht jede Annahme dieses Modells zusammen.
Das Session-Modell kollabiert. KI-Agenten operieren kontinuierlich ohne Sessions, was ihre Überwachung anhand von Identitätssignalen wie IP-Adresse, Standort oder Gerätekontext erheblich erschwert[2]. Es gibt kein Login-Ereignis, an dem eine Policy-Entscheidung ansetzen könnte.
Zugangsdaten werden geerbt, nicht begrenzt. Agenten ermitteln ihren Zugriffsbedarf dynamisch zur Laufzeit, sodass vorab provisionierte Berechtigungssätze entweder zu weit greifen - was den Blast Radius vergrößert - oder zu eng sind und Fehler verursachen, die Teams durch noch umfangreichere Zugriffsgewährungen beheben[3]. Das praktische Ergebnis: Agenten erhalten am Ende den vollständigen Berechtigungssatz des Entwicklers, der sie provisioniert hat.
Sub-Agenten zerstören die Verantwortlichkeit. Wenn Agenten Aufgaben an Sub-Agenten delegieren, zerbricht die Verantwortlichkeitskette - kein System verfolgt, welcher Agent welchen Sub-Agenten autorisiert hat oder welche Berechtigungen dabei weitergegeben wurden[4]. Erbt ein Sub-Agent die vollständigen Zugangsdaten eines Menschen, weitet sich die Angriffsfläche über die gesamte Kette aus.
Nicht-Determinismus macht den Scope unvorhersehbar. Ein Agent, der gebeten wird, Kundensupport-Tickets zusammenzufassen, kann schlussfolgern, dass der Rechnungsverlauf die Zusammenfassung verbessern würde. Ist die Billing-API unter den geerbten Zugangsdaten des Agenten erreichbar, ruft er sie auf - nicht böswillig, nicht aufgrund einer Fehlkonfiguration, sondern weil das Modell den Aufruf als nützlich eingestuft hat und nichts ihn blockiert hat[5].
Das Ergebnis ist eine neue Klasse von Zombie-Identitäten. Wenn überprivilegierte Agenten ihre Projekte überleben, werden sie häufig zu Zombie-Agenten - verwaisten Identitäten mit gültigen Zugangsdaten, aktiven Berechtigungen und keinem menschlichen Eigentümer[6]. Ihr Offboarding-Prozess war nie darauf ausgelegt, sie zu erfassen.
Der MCP-Reality-Check: Ein Protokoll ohne Authentifizierungspflicht
Das Model Context Protocol hat sich zum De-facto-Standard für die Anbindung von KI-Agenten an Tools und Daten entwickelt. MCP überschritt 97 Millionen monatliche SDK-Downloads (Python und TypeScript zusammen), und die Linux Foundation verwaltet das Protokoll nun über die Agentic AI Foundation, die von Anthropic, OpenAI und Block mitgegründet wurde - mit Google, Microsoft, AWS und Cloudflare als Platinum-Mitglieder[7].
Die Governance-Geschichte klingt solide. Der Sicherheitsstatus der deployed Server ist es nicht.
Ein Scan von mehr als 500 produktiven MCP-Endpunkten ergab, dass 38 % der Server auf MCP-Protokollebene keinerlei Authentifizierung aufweisen - das bedeutet, jeder KI-Agent oder jeder HTTP-Client kann alle verfügbaren Tools aufzählen und sie in vielen Fällen direkt ausführen[8]. Zu den ungeschützten Servern gehören CI/CD-Pipeline-Trigger, Datenbankabfrage-Schnittstellen und Cloud-Infrastruktur-Steuerungen.
Ein Folgescan von Trend Micro ergab, dass sich die Zahl der exponierten MCP-Server auf 1.467 fast verdreifacht hatte - 1.227 davon nutzten noch immer den längst veralteten SSE-Transport[9]. Das Expositionsproblem hat die Cloud erreicht.
Die Spezifikation gibt eine klare Antwort darauf. MCPs OAuth-2.1-Profil schreibt PKCE für alle Authorization-Code-Flows vor, entfernt den Implicit Grant und den Resource-Owner-Password-Credentials-Grant vollständig und verlangt, dass Tokens über Resource Indicators (RFC 8707) an einen bestimmten MCP-Server gebunden werden[10]. Das Problem: "Autorisierung ist OPTIONAL für MCP-Implementierungen" - und die meisten Betreiber nutzen genau diese Option.
Only 8.5% of MCP servers use OAuth — the rest rely on static API keys, basic credentials, or nothing at all (BlueRock Security analysis of ~7,000 public servers). Implementing OAuth 2.1 + PKCE is not a nice-to-have; it's the minimum viable security posture for any agent touching production systems.
Fünf Muster, die tatsächlich funktionieren
1. Kurzlebige, begrenzte Tokens - keine langlebigen API-Keys
Die wirkungsvollste Einzelmaßnahme, die Platform-Teams ergreifen können, ist die Abschaffung dauerhafter Zugangsdaten für Agenten. Für autonome Systeme sollte das Least-Privilege-Prinzip als Laufzeit-Entscheidungsmodell behandelt werden, nicht als einmalige Zugriffsgewährung - das effektivste Muster kombiniert Workload-Identität, absichtsbasierte Autorisierung und zeitbasierten Zugriff bei der Credential-Ausstellung[11].
In der Praxis: Der Agent weist zunächst seine Identität über eine Workload-Identität nach (SPIFFE SVID, Kubernetes OIDC oder Cloud-native Attestierung), fordert nur den für die aktuelle Aufgabe benötigten Zugriff an und verliert diesen Zugriff, sobald die Aufgabe abgeschlossen ist. Keine dauerhaften Berechtigungen werden wiederhergestellt. Keine permanente Erweiterung der Basisrolle.
Speziell für MCP gilt: Gestalten Sie OAuth-Scopes pro Tool - beispielsweise mcp:tool:read_file:read -, sodass jedes Token nur die exakt benötigte Aktion gewährt[10]. Resource Indicators (RFC 8707) binden jedes Token an einen einzigen MCP-Server und verhindern serverübergreifendes Token-Replay.
2. JIT-Zugriff für privilegierte Operationen
JIT-Zugriff ist die Brücke zwischen null dauerhaften Berechtigungen und Entwickler-Produktivität. Wenn ein Agent legitim eine gesperrte Berechtigung benötigt, wird die Anfrage über einen Genehmigungspfad geleitet - eingereicht über Slack oder ein Entwicklerportal, in Sekunden genehmigt, für die Dauer der Aufgabe gewährt und nach Abschluss automatisch entzogen.
Microsofts Defense-in-Depth-Leitfaden für autonome Agenten empfiehlt, Fähigkeiten auf die Dauer einer bestimmten Aufgabe zu begrenzen, wobei aufgabenbezogene Berechtigungen bevorzugt werden, da sie natürlich ablaufen, wenn die Aufgabe abgeschlossen ist[12]. Zeitbasierte Berechtigungen sind der Fallback, wenn aufgabenbasierte Grenzen nicht umsetzbar sind.
Das zentrale Designprinzip: Die Frage lautet nicht "Sollten wir das einschränken?", sondern "Haben wir das explizit erlaubt?" Standard: Ablehnen. Ausnahme: explizite Erlaubnis.
3. Policy-as-Code auf der Tool-Ebene
Autorisierungslogik in den Anwendungscode des Agenten einzubetten ist ein Governance-Anti-Pattern - sie ist für Security-Teams unsichtbar, lässt sich nicht isoliert testen und überlebt Agenten-Updates nicht. Die Alternative ist die Auslagerung von Richtlinien / Policies in eine deklarative Schicht, die jede vom Agenten initiierte Aktion vor der Ausführung bewertet.
Ein Least-Privilege-KI-Agenten-Gateway-Muster mit Open Policy Agent (OPA) validiert jede Anfrage, autorisiert sie mittels Policy-as-Code und führt sie in kurzlebigen, isolierten Umgebungen mit eingebetteter Observability über OpenTelemetry aus[13]. Das Gateway vermittelt jede Anfrage und begrenzt die Ausführung auf die minimal erforderlichen Berechtigungen.
Policy-as-Code liefert drei Dinge, die Ticket-Warteschlangen nicht können: versionskontrollierte Zugriffsregeln, automatisierte Durchsetzung mit Maschinengeschwindigkeit und einen testbaren Vertrag zwischen dem, was der Agent tun darf, und dem, was er tatsächlich tut.
4. Eine vertrauenswürdige Agenten-Registry
82 % der Unternehmen haben im vergangenen Jahr bisher unbekannte KI-Agenten in ihrer Umgebung entdeckt, 41 % berichten, dass dies mehrfach vorkam - Shadow-IT-Agenten entstehen am häufigsten in internen Automatisierungs- oder Scripting-Umgebungen und in von Entwicklern erstellten Workflows[14].
Was man nicht sehen kann, lässt sich nicht steuern. Eine vertrauenswürdige Agenten-Registry löst das Discovery-Problem, indem sie die Registrierung zur Voraussetzung für das Deployment macht - nicht zum Nachgedanken. Jeder Agent erhält eine eindeutige, verifizierbare Identität. Jeder MCP-Server erhält einen Eintrag in der Registry mit seinem genehmigten Tool-Set, dem verantwortlichen Team und seiner Zugriffs-Policy. Agenten, die nicht in der Registry stehen, erhalten keine Tokens.
Das ist dasselbe Muster, das bei menschlichen Identitäten funktioniert: Zugriffsrechte werden nicht an User vergeben, die nicht im Verzeichnis stehen. Wenden Sie dieselbe Logik auf Maschinen an.
5. Least-Privilege-Prinzip pro Tool/Scope - nicht pro Agent
Die Granularität ist entscheidend. Einem Agenten "Lesezugriff auf GitHub" zu gewähren ist kein Least-Privilege-Prinzip - es ist eine weitreichende dauerhafte Berechtigung mit einem engen Label. Die Zugriffskontrolle muss am Punkt der Tool-Ausführung stattfinden, wo die Anfrage des Agenten anhand seines definierten Scopes geprüft wird[5].
Konkret: Ein Code-Review-Agent sollte list_pull_requests und read_file auf bestimmten Repositories aufrufen können. Er sollte nicht in der Lage sein, delete_branch, push_commit oder read_secrets aufzurufen. Das sind unterschiedliche Tools, und jedes benötigt eine eigene explizite Autorisierungsentscheidung.
Gartner identifiziert etwa 40 Tool-Definitionen als den Schwellenwert, ab dem Agenten-Latenz und Token-Kosten messbar steigen - jede in den Kontext eines Agenten geladene Tool-Definition verbraucht Tokens, unabhängig davon, ob das Tool jemals aufgerufen wird[5]. Das Least-Privilege-Prinzip ist nicht nur eine Sicherheitskontrolle, sondern auch ein Hebel für operative Effizienz und Kostenkontrolle.
Self-Service innerhalb von Leitplanken: Das Developer-Experience-Problem
Entwickler umgehen Governance nicht aus böser Absicht - sondern wegen Reibung. Eine Ticket-Warteschlange, die drei Tage braucht, um eine neue MCP-Server-Verbindung zu genehmigen, ist eine Ticket-Warteschlange, die umgangen wird. Das Ziel ist, den geregelten Weg zum Weg des geringsten Widerstands zu machen.
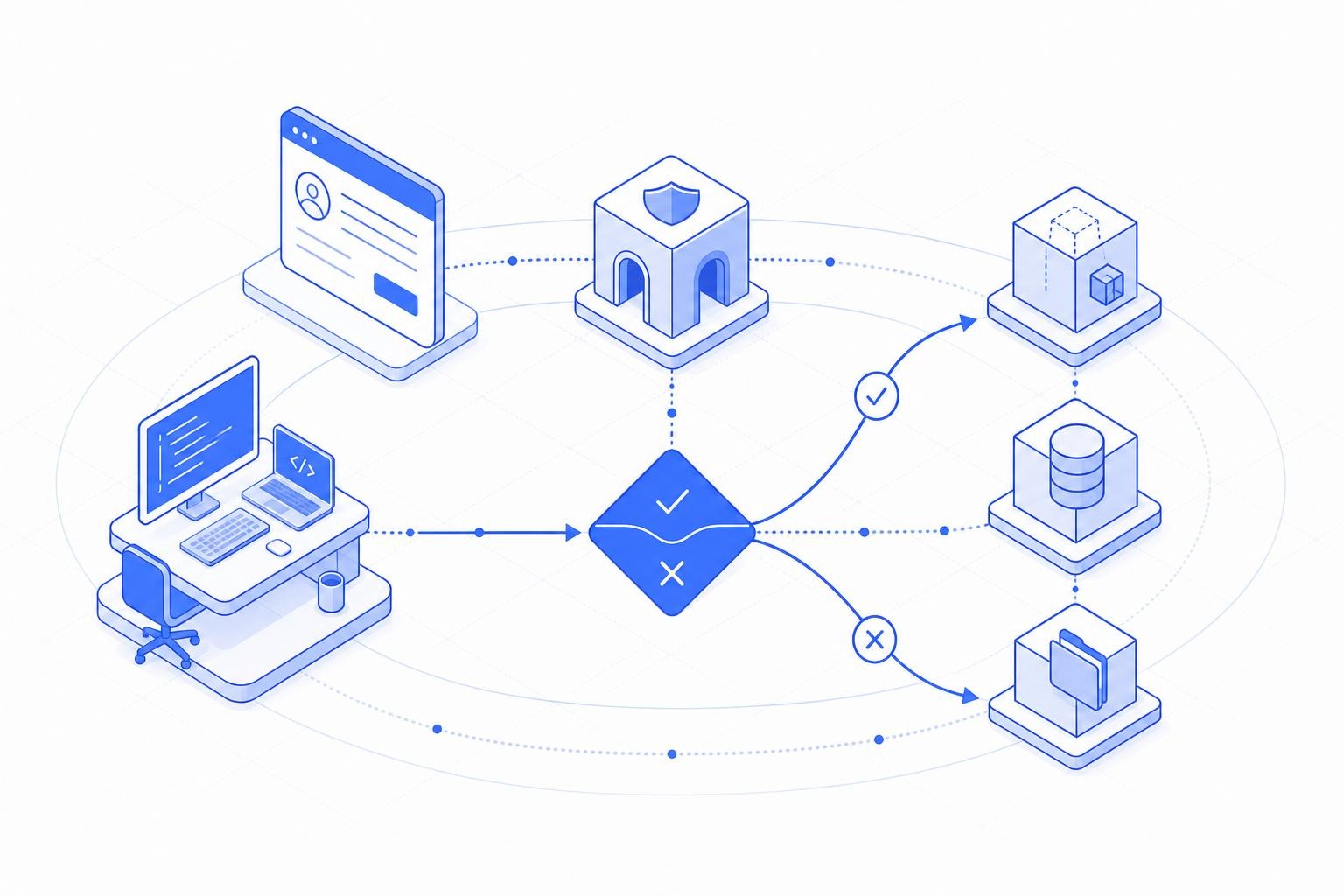
Die Architektur, die funktioniert, sieht so aus:
- Ein Self-Service-Katalog mit vorab genehmigten Agenten-Personas und Tool-Bundles. Ein Entwickler, der einen Code-Review-Agenten deployed, wählt aus einem geregelten Menü - nicht aus einem leeren Berechtigungsformular.
- Automatisierte Policy-Auswertung, die risikoarme Anfragen sofort genehmigt und erhöhte Anfragen mit vollständigem Kontext an einen menschlichen Genehmiger weiterleitet.
- Infrastructure-as-Code-Integration, sodass Agenten über Terraform oder Helm registriert werden können, mit Zugriffs-Policies, die neben dem Deployment-Manifest deklariert werden.
- Automatisiertes Lifecycle-Management, das Agenten-Zugangsdaten an den Deployment-Lifecycle koppelt - wenn der Agent undeployed wird, laufen die Tokens automatisch ab.
Das Agent-Control-Plane-Muster ermöglicht es Entwicklern, Agenten über Terraform zu registrieren und bestehende Tokens wie Kubernetes OIDC gegen spezifisch begrenzte temporäre Tokens auszutauschen, die automatisch ablaufen, wenn der Agent undeployed wird - mehr Sicherheit ohne neuen Engpass im Entwicklungs-Workflow[15].
Die Governance-Last verschiebt sich von "jede Anfrage manuell genehmigen" zu "die Policy einmal definieren, automatisch durchsetzen". Das ist ein Modell, das schlanke Platform-Teams tatsächlich aufrechterhalten können.
Genau diese Lücke schließt Iden - einheitliche Governance für menschliche und nicht-menschliche Identitäten (NHIs), mit feingranularer Zugriffskontrolle bis auf Tool- und Scope-Ebene, ohne den Engpass einer Ticket-Warteschlange. Für einen tieferen Einblick in die Zugriffsmuster lesen Sie unseren Schritt-für-Schritt-Guide zur Absicherung von KI-Agenten-Zugriffen und Wie man ein Agentic Identity Governance Framework aufbaut.
Die Governance-Vertrauenslücke: Ein Entscheidungstool
Bevor Sie Ihren Implementierungsplan erstellen, hilft es zu wissen, wo Ihr aktueller Sicherheitsstatus tatsächlich steht. Nutzen Sie dieses Tool, um die Reife Ihrer Agenten-Governance zu bewerten und eine priorisierte Maßnahmenliste zu erhalten.
Implementierungs-Checkliste für Platform-Teams
Das ist die konkrete Abfolge. Arbeiten Sie sie der Reihe nach durch - jede Schicht baut auf der vorherigen auf.
Run a discovery sweep across your cloud accounts, CI/CD pipelines, developer workstations, and SaaS platforms. Catalog every agent identity, its owning team, its credential type, and every MCP server it connects to. If you can't enumerate them, you can't govern them.
Every agent needs an accountable human owner — not a team alias, a named individual. This is the prerequisite for access reviews, incident response, and lifecycle management. Agents without owners are zombie identities waiting to happen.
Require the authorization code flow with PKCE (S256 method) on every internet-accessible MCP server. Remove implicit grants. Implement resource indicators (RFC 8707) to bind tokens to specific servers. This is the MCP spec's security baseline — treat it as mandatory, not optional.
Audit every agent credential. Replace static API keys with workload identity attestation (SPIFFE SVIDs, Kubernetes OIDC, or cloud-native equivalents) that issue short-lived tokens per task. Set maximum token TTLs of 15–60 minutes for most agent operations.
Define the exact tool set each agent persona is authorized to call. Externalize this policy into OPA or a comparable policy engine. Enforce at the gateway layer — not inside agent application code. Every tool invocation should pass or fail against a declared policy.
Create a governed menu of pre-approved agent personas and tool bundles. Route low-risk requests to instant automated approval. Route elevated requests to a human approver with full context. Integrate registration into your IaC workflow so agents are governed from their first deployment.
Log every tool invocation with: agent identity, human owner, tool called, parameters (sanitized), timestamp, and policy decision. Store logs in an immutable, queryable system. This is your forensic trail when something goes wrong — and the evidence your auditors will ask for.
Tie agent credential validity to the deployment lifecycle. When an agent is deprovisioned, its tokens should expire automatically. Run quarterly access reviews on all agent identities the same way you review human access. Quarantine deprecated agent roles rather than leaving them active with standing permissions.
Die Governance-Lücke ist strukturell, nicht kosmetisch
Nur 18 % der Security-Verantwortlichen sind sehr zuversichtlich, dass ihre aktuellen IAM-Systeme KI-Agenten-Identitäten effektiv verwalten können - der Rest bewegt sich irgendwo zwischen mäßig zuversichtlich und überhaupt nicht[16]. Das ist kein Tooling-Problem. Es ist ein architektonisches. IAM-Systeme, die für menschliche Sessions, passwortbasierte Authentifizierung und menschliche Zugriffsgeschwindigkeiten entwickelt wurden, waren nie für autonome Agenten ausgelegt, die kontinuierlich operieren, Sub-Agenten spawnen und Hunderte von API-Aufrufen pro Minute durchführen.
Die Muster in diesem Guide - kurzlebige Tokens, JIT-Zugriff, Policy-as-Code, eine vertrauenswürdige Registry, Least-Privilege-Prinzip pro Tool - sind nicht neu. Es sind dieselben Prinzipien, die bei der menschlichen Identity Governance funktionieren, angepasst an Maschinengeschwindigkeit. Der Unterschied besteht darin, dass Agenten Durchsetzung zur Laufzeit erfordern, bei jeder Tool-Ausführung, mit automatisiertem Lifecycle-Management, das nicht davon abhängt, dass ein Mensch daran denkt, Zugriffe zu entziehen.
Platform-Teams, die diese Infrastruktur jetzt aufbauen, sichern sich einen sich kumulierenden Sicherheitsvorteil. Jeder Agent, der in einer geregelten Umgebung deployed wird, ist eine Zombie-Identität weniger, ein dauerhafter Credential weniger, ein unüberwachter Ausführungspfad weniger in Ihre Produktionssysteme.
Die Ticket-Warteschlange ist nicht die Antwort. Geregelter Self-Service ist es.